- In-memory storage completely relies on them: all the indexes there are of Index type.
- The same is about RSE. Any record it returns is actually a Tuple.
- Finally, any Entity internally uses DifferentialTuple to remember original and updated state. Protected Entity.Tuple is exactly this DifferentialTuple. So e.g. to check if field with name fieldName is already loaded (available), you can use this code inside Entity method: this.Tuple.IsAvailable(this.Type.Fields[fieldName]). This means they're used to store internally cached Entity state during its lifetime.
And as I wrote earlier, our Tuples are different from Tuples that will be available in .NET 4.0. Mainly, because they're fully virtualized. You can provide any implementation of them you like. E.g. we use TransformedTuple ancestors or DifferentialTuple, that implement their own field access logic.
This is quite convenient, but pretty costly as well: initially we've been using virtual generic methods to allow such "rich" Tuple field access logic to be overridden, and finally failed with this: virtual generic method calls are quite costly, because in fact they rely on dictionary lookups. That was quite disappointing... So finally we switched to version with boxing - it was almost 2 times faster on tight loop tests.
But frequent boxing is bad as well: it fills generation 0 faster making CLR to run garbage collections in generation 0 more frequently. Cost of "releasing" unused boxed objects is zero, but each GC implies significant amount of work anyway. You might assume the CPU cost of Gen0 GC in real-life application is nearly constant, so it's a good idea to decrease the amount of such collections. But how? The only way is to allocate less. We know this, and frankly speaking, our entity materialization process was already highly optimized from this point - there are no any temporary per-object allocations everywhere at all... Everywhere, if we could exclude Tuples :) On the other hand, AFAIK currently we have ~ 2 box-unbox operations per each field we materialize just because of this! Taking into account this fact and materialization performance, you can imagine how well our materialization pipeline is optimized.
Now the good news: last Friday I invented a way to get rid of this lack. The idea behind is to "emulate" generic virtual method calls (internally relying on dictionaries) via regular virtual method calls returning delegates based on field index (relying on array access).
We already measured this must raise up Tuples performance at least by 50%, if there are no "external" RAM allocations at all. In reality the numbers will be even better: we expect 80-120% increase in case if "external" RAM allocations happen.
The numbers we've got on tests for real-life case:
Old Tuples with boxing:
- Setter: Operations: 23,323 M/s.
- Getter: Operations: 24,629 M/s.
New Tuples without boxing:
- Setter: Operations: 70,954 M/s.
- Getter: Operations: 81,680 M/s.
Currently new logic isn't implemented yet, although we simulated its particular case on tests. If you're interested in ideas behind and exact implementation, see Xtensive.Core\Xtensive.Core.Tests\DotNetFramework\NewTupleLogicTest.cs from the latest nightly build.
We're going to implement new logic in v4.0.6 release as well. It must be relatively simple, since it won't lead to public API change. Hopefully, this will noticeably increase our materialization performance further.
The issue to track: 382.

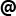

No comments:
Post a Comment